Navigating Concurrent Access: A Deep Dive into Concurrent Data Structures
Related Articles: Navigating Concurrent Access: A Deep Dive into Concurrent Data Structures
Introduction
With great pleasure, we will explore the intriguing topic related to Navigating Concurrent Access: A Deep Dive into Concurrent Data Structures. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Navigating Concurrent Access: A Deep Dive into Concurrent Data Structures
- 2 Introduction
- 3 Navigating Concurrent Access: A Deep Dive into Concurrent Data Structures
- 3.1 Understanding the Need for Synchronization
- 3.2 Concurrent Maps: A Solution for Synchronized Access
- 3.3 Mechanisms for Synchronization in Concurrent Maps
- 3.4 Benefits of Using Concurrent Maps
- 3.5 Considerations When Using Concurrent Maps
- 3.6 FAQs:
- 3.7 Tips:
- 3.8 Conclusion:
- 4 Closure
Navigating Concurrent Access: A Deep Dive into Concurrent Data Structures
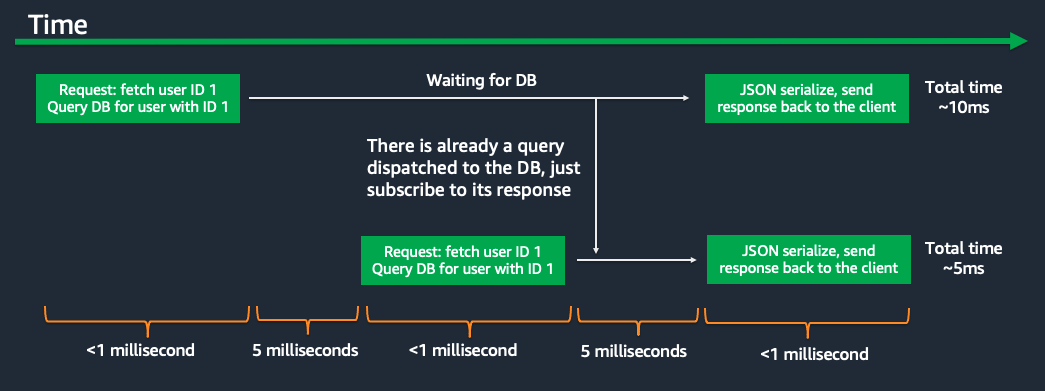
In the realm of software development, the ability to manage concurrent access to shared resources is paramount. This is especially true in multi-threaded environments where multiple threads or processes can potentially access and modify the same data simultaneously. Uncontrolled concurrent access can lead to data corruption, race conditions, and unpredictable program behavior. To ensure data integrity and maintain program stability, developers rely on a range of techniques and data structures designed for synchronized access. Among these, concurrent maps stand out as a powerful tool for managing shared key-value pairs in a multi-threaded setting.
Understanding the Need for Synchronization
The crux of the synchronization problem lies in the potential for data inconsistency when multiple threads attempt to modify the same data concurrently. Consider a scenario where two threads, Thread A and Thread B, attempt to increment a shared counter variable. If both threads read the current value of the counter, say 5, and then attempt to increment it, each thread might independently add 1 to the value, resulting in a final value of 6 instead of the expected 7. This discrepancy arises because the increment operation is not atomic; it involves multiple steps (read, increment, write) that can be interrupted by other threads.
To prevent such inconsistencies, synchronization mechanisms are employed. These mechanisms ensure that critical operations, such as reading and writing to shared data, are executed atomically, preventing interference from other threads.
Concurrent Maps: A Solution for Synchronized Access
Concurrent maps, also known as thread-safe maps, are specialized data structures designed for efficient and synchronized access in multi-threaded environments. They provide a robust solution for managing shared key-value pairs while ensuring data integrity and preventing race conditions.
Key Features of Concurrent Maps:
- Thread Safety: Concurrent maps are inherently thread-safe, meaning that multiple threads can access and modify the map concurrently without causing data corruption. This is achieved through internal synchronization mechanisms that ensure atomic operations on the map’s data.
- Efficient Operations: Concurrent maps are optimized for efficient operations, such as insertion, deletion, retrieval, and iteration. They leverage concurrency control techniques to minimize contention between threads, enabling efficient performance even under high concurrency.
- Scalability: Concurrent maps are designed to scale well with increasing thread counts and data volumes. Their internal synchronization mechanisms are typically designed to handle concurrent access from multiple threads efficiently.
Common Implementations:
Several popular programming languages and libraries provide implementations of concurrent maps:
-
Java: The
ConcurrentHashMapclass in thejava.util.concurrentpackage offers a thread-safe implementation of a hash map. -
C++: The
std::unordered_mapclass in the C++ standard library can be used with synchronization mechanisms like mutexes or atomic operations to achieve thread-safe access. -
Python: The
concurrent.futuresmodule in Python provides tools for managing concurrent tasks, and thethreadingmodule can be used to implement thread-safe data structures, including maps. -
Go: Go’s built-in
maptype is not inherently thread-safe, but it can be made thread-safe using synchronization primitives like mutexes or channels.
Mechanisms for Synchronization in Concurrent Maps
Concurrent maps employ various techniques to ensure synchronized access and data integrity. Some common approaches include:
- Mutex Locks: Mutex locks are synchronization primitives that allow only one thread to access a critical section of code at a time. In concurrent maps, a mutex lock can be used to protect the map’s internal data structures during operations like insertion, deletion, and retrieval.
- Read-Write Locks: Read-write locks offer a more fine-grained approach to synchronization. They allow multiple threads to read the map concurrently, but only one thread can write to the map at a time. This can improve performance in scenarios where read operations are significantly more frequent than write operations.
- Atomic Operations: Atomic operations are indivisible operations that cannot be interrupted by other threads. Concurrent maps can leverage atomic operations, such as atomic compare-and-swap (CAS), to ensure that operations like insertion or deletion are completed atomically.
- Lock-Free Algorithms: Lock-free algorithms avoid the use of locks altogether. They utilize techniques like compare-and-swap operations to ensure atomic updates to shared data. Lock-free algorithms can offer better performance in highly concurrent scenarios by eliminating the overhead of acquiring and releasing locks.
Benefits of Using Concurrent Maps
The use of concurrent maps offers several significant benefits in multi-threaded applications:
- Data Integrity: Concurrent maps ensure data integrity by preventing race conditions and data corruption. This is crucial for maintaining the consistency and reliability of shared data in multi-threaded environments.
- Improved Performance: Concurrent maps are designed for efficient concurrent access, allowing multiple threads to operate on the map simultaneously without significant performance degradation.
- Simplified Development: Concurrent maps abstract away the complexities of thread synchronization, allowing developers to focus on the application logic rather than managing low-level synchronization mechanisms.
- Scalability: Concurrent maps are designed to scale well with increasing thread counts and data volumes, enabling applications to handle high concurrency and large datasets efficiently.
Considerations When Using Concurrent Maps
While concurrent maps offer significant advantages, there are some considerations to keep in mind when using them:
- Performance Overhead: Synchronization mechanisms in concurrent maps can introduce some performance overhead compared to non-concurrent data structures. However, the performance benefits of thread-safe access often outweigh the overhead in multi-threaded applications.
- Complexity: Implementing and managing concurrent maps can be more complex than using traditional data structures. Developers need to understand the synchronization mechanisms and potential pitfalls to avoid introducing concurrency bugs.
- Choice of Implementation: Different implementations of concurrent maps may have varying performance characteristics and trade-offs. It’s important to choose an implementation that best suits the specific needs of the application.
FAQs:
Q: What is the difference between a regular map and a concurrent map?
A: A regular map is not thread-safe, meaning that multiple threads accessing it concurrently can lead to data corruption. Concurrent maps are designed for thread-safe access, ensuring data integrity in multi-threaded environments.
Q: How do concurrent maps handle concurrent access from multiple threads?
A: Concurrent maps employ various synchronization mechanisms, such as mutex locks, read-write locks, atomic operations, and lock-free algorithms, to ensure that operations on the map are executed atomically and without interference from other threads.
Q: Are concurrent maps always the best choice for multi-threaded applications?
A: While concurrent maps are a powerful tool for managing shared data in multi-threaded environments, they may not always be the best choice. If the application involves infrequent or low-concurrency access to shared data, using a regular map with appropriate synchronization mechanisms might be sufficient and more efficient.
Q: What are some common pitfalls to avoid when using concurrent maps?
A: Some common pitfalls include:
- Deadlock: Deadlock can occur when two or more threads are blocked indefinitely waiting for each other to release a resource.
- Livelock: Livelock occurs when threads repeatedly attempt to acquire a resource but are constantly interrupted by other threads, leading to a situation where no progress is made.
- Race Conditions: Race conditions occur when the outcome of an operation depends on the unpredictable order in which threads access and modify shared data.
Q: How can I ensure the correct use of concurrent maps in my application?
A: To ensure the correct use of concurrent maps, it’s crucial to:
- Understand the synchronization mechanisms used by the chosen implementation.
- Carefully manage the critical sections of code that access the concurrent map.
- Thoroughly test the application under various concurrency scenarios to identify and resolve potential issues.
Tips:
- Choose the right implementation: Select a concurrent map implementation that best suits the specific needs of the application in terms of performance, scalability, and synchronization mechanisms.
- Minimize critical sections: Keep the critical sections of code that access the concurrent map as small as possible to reduce contention between threads.
- Use appropriate synchronization primitives: Employ the appropriate synchronization primitives, such as mutex locks, read-write locks, or atomic operations, based on the specific requirements of the application.
- Test thoroughly: Thoroughly test the application under various concurrency scenarios to identify and resolve potential issues related to synchronization and data integrity.
Conclusion:
Concurrent maps play a vital role in enabling efficient and synchronized access to shared data in multi-threaded environments. They provide a robust solution for managing key-value pairs while ensuring data integrity and preventing race conditions. Understanding the key features, synchronization mechanisms, and potential pitfalls of concurrent maps is essential for developers building reliable and scalable multi-threaded applications. By carefully choosing the right implementation and employing best practices, developers can leverage the power of concurrent maps to build robust and efficient applications that can handle high concurrency and large datasets.





Closure
Thus, we hope this article has provided valuable insights into Navigating Concurrent Access: A Deep Dive into Concurrent Data Structures. We thank you for taking the time to read this article. See you in our next article!