The Essence of Uniqueness: Exploring the Importance of Distinct Keys in Data Structures
Related Articles: The Essence of Uniqueness: Exploring the Importance of Distinct Keys in Data Structures
Introduction
In this auspicious occasion, we are delighted to delve into the intriguing topic related to The Essence of Uniqueness: Exploring the Importance of Distinct Keys in Data Structures. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: The Essence of Uniqueness: Exploring the Importance of Distinct Keys in Data Structures
- 2 Introduction
- 3 The Essence of Uniqueness: Exploring the Importance of Distinct Keys in Data Structures
- 3.1 Understanding the Concept of Keys
- 3.2 The Significance of Uniqueness
- 3.2.1 1. Hash Tables
- 3.2.2 2. Dictionaries and Maps
- 3.2.3 3. Databases
- 3.3 Consequences of Non-Unique Keys
- 3.4 Ensuring Key Uniqueness: Strategies and Techniques
- 3.5 FAQs: Addressing Common Concerns
- 3.6 Tips for Implementing Key Uniqueness
- 3.7 Conclusion: The Foundation of Data Integrity
- 4 Closure
The Essence of Uniqueness: Exploring the Importance of Distinct Keys in Data Structures
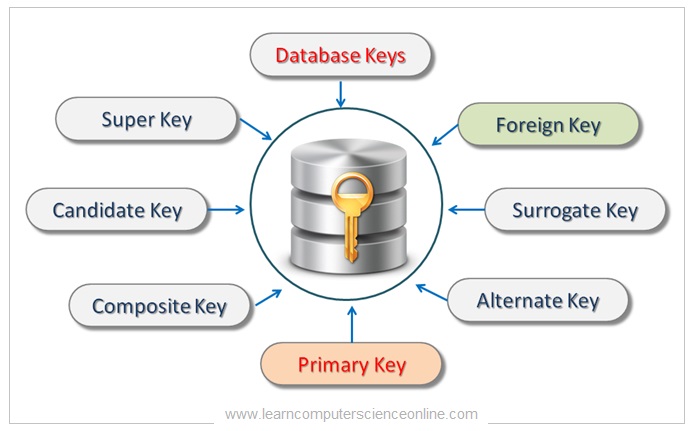
In the realm of data organization and retrieval, the concept of a "key" plays a pivotal role. Keys serve as unique identifiers, enabling efficient access and manipulation of data within various structures. One fundamental principle governing these keys is the necessity for them to be distinct, ensuring clarity, consistency, and reliable performance in data operations. This article delves into the significance of this principle, exploring its implications across various data structures and highlighting its crucial role in maintaining data integrity.
Understanding the Concept of Keys
A key, in the context of data structures, acts as a label or identifier associated with a specific data element. This element could be a single value, a group of values, or an entire record within a larger dataset. The key’s primary function is to provide a means of locating and retrieving the associated data element quickly and efficiently.
Imagine a library with thousands of books. Each book has a unique identification number – its key – that allows librarians to find it on the shelves effortlessly. Similarly, in computer systems, keys enable the efficient organization and retrieval of information, whether it’s a single piece of data or an entire database.
The Significance of Uniqueness
The principle of uniqueness dictates that each key within a data structure must be distinct, preventing any two elements from sharing the same identifier. This seemingly simple principle underpins the efficiency and reliability of numerous data operations. Let’s examine its importance through the lens of various data structures:
1. Hash Tables
Hash tables, also known as hash maps, are a fundamental data structure that utilizes keys for rapid data access. They employ a hash function, which transforms keys into numerical indices within a table. The uniqueness of keys is paramount here, as it ensures that each key maps to a distinct index, preventing collisions and maintaining the integrity of the data structure.
Imagine a hash table storing information about customers. Each customer is assigned a unique ID (the key) that maps to their associated data. If two customers shared the same ID, the hash function would map them to the same index, leading to data corruption and retrieval errors.
2. Dictionaries and Maps
Dictionaries and maps are data structures that associate keys with values. Think of them as key-value pairs, where each key uniquely identifies a specific value. The uniqueness of keys guarantees that each key maps to only one value, ensuring unambiguous retrieval and manipulation of data.
For example, a dictionary might store the names of cities and their corresponding populations. Each city name (the key) is unique, allowing for the retrieval of the correct population without ambiguity.
3. Databases
In relational databases, keys are used to identify and link tables. The primary key, a unique identifier for each record within a table, plays a crucial role in maintaining data integrity and enabling efficient data retrieval. Foreign keys, which link records in different tables, rely on the uniqueness of primary keys to establish relationships and ensure data consistency.
For instance, a database storing customer information might have a table for customers and another for orders. Each customer has a unique ID (primary key), and each order references a specific customer ID (foreign key). The uniqueness of customer IDs ensures that orders are correctly linked to their respective customers, preventing data duplication and inconsistencies.
Consequences of Non-Unique Keys
The failure to enforce uniqueness in keys can lead to a myriad of problems, undermining the efficiency and reliability of data operations:
-
Data Corruption: Non-unique keys can result in data overwriting, where data associated with one key is accidentally overwritten by data associated with another key. This can lead to inaccurate data, rendering the data structure unreliable.
-
Performance Degradation: Hash tables and other data structures rely on unique keys to maintain efficient access. Non-unique keys can lead to collisions, forcing the system to perform additional comparisons and searches, slowing down data retrieval and manipulation.
-
Inconsistency and Ambiguity: Non-unique keys can introduce ambiguity when retrieving data, making it difficult to determine which data element is associated with a particular key. This can lead to incorrect data being retrieved and processed, compromising the integrity of the system.
-
Data Duplication: Non-unique keys can result in data duplication, where the same data is stored multiple times under different keys. This can waste storage space and make data management more complex.
Ensuring Key Uniqueness: Strategies and Techniques
Maintaining the uniqueness of keys is crucial for data integrity and efficiency. Various strategies and techniques are employed to ensure this principle:
-
Data Validation: During data input, it’s essential to validate that keys are unique before they are stored in the data structure. This can be achieved through checks against existing keys or by using algorithms that generate unique identifiers.
-
Data Indexing: Databases and other data structures often utilize indexing to optimize data retrieval. Indexes typically store keys along with their associated data pointers, facilitating rapid searches and ensuring the uniqueness of keys.
-
Data Integrity Constraints: Relational databases employ data integrity constraints to enforce data consistency and prevent violations of uniqueness. These constraints can be defined during database design, ensuring that keys are unique and relationships between tables are maintained.
-
Unique Identifier Generation: Algorithms like UUID (Universally Unique Identifier) and GUID (Globally Unique Identifier) generate unique identifiers, ensuring that each key is distinct. These algorithms are widely used in distributed systems and applications where globally unique identifiers are required.
FAQs: Addressing Common Concerns
Q: What happens if two keys are accidentally assigned the same value?
A: If two keys share the same value, it can lead to data corruption, performance degradation, and ambiguity. Data associated with one key might be overwritten by data associated with the other key, resulting in inaccurate information.
Q: Can I use non-unique keys if I’m only storing a small amount of data?
A: While it might seem acceptable for small datasets, using non-unique keys can lead to problems as the dataset grows. It’s best practice to always enforce key uniqueness to avoid potential issues later.
Q: What are the advantages of using unique keys in a database?
A: Unique keys ensure data integrity, enable efficient data retrieval, and simplify data management. They facilitate relationships between tables, prevent data duplication, and enhance the overall reliability of the database.
Q: Are there any specific guidelines for choosing unique keys?
A: Choosing keys should be done with careful consideration. They should be concise, meaningful, and easily distinguishable. It’s also essential to ensure that the chosen key is unlikely to be duplicated in the future.
Tips for Implementing Key Uniqueness
- Use a robust data validation mechanism: Implement thorough checks to ensure that keys are unique before storing them in the data structure.
- Employ appropriate data indexing techniques: Use indexes to optimize data retrieval and ensure the uniqueness of keys.
- Leverage data integrity constraints in databases: Define constraints to enforce data consistency and prevent violations of key uniqueness.
- Consider using unique identifier generation algorithms: Utilize algorithms like UUID or GUID to generate globally unique identifiers.
Conclusion: The Foundation of Data Integrity
The principle of key uniqueness is a cornerstone of data integrity and efficiency. It ensures that each data element is uniquely identified, enabling reliable data retrieval, manipulation, and management. By embracing this principle, developers and data managers can create robust and reliable data structures that form the foundation of modern information systems. As data complexity and volume continue to grow, the importance of unique keys will only become more pronounced, serving as a critical element in maintaining data integrity and enabling efficient data operations.




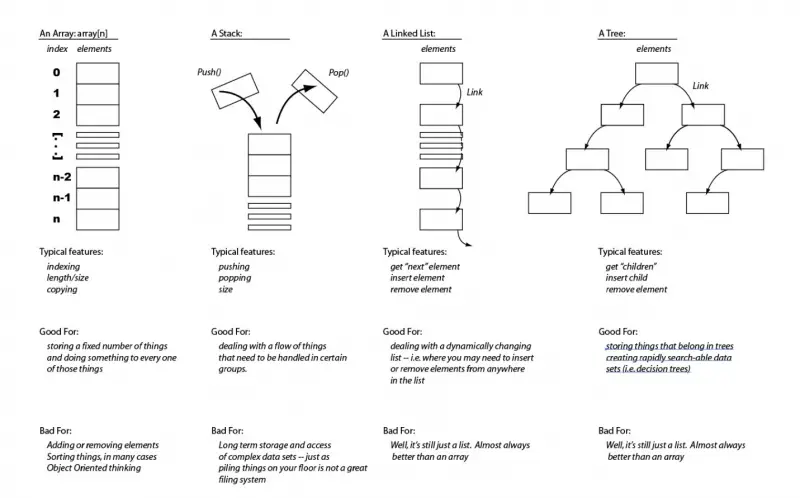


Closure
Thus, we hope this article has provided valuable insights into The Essence of Uniqueness: Exploring the Importance of Distinct Keys in Data Structures. We hope you find this article informative and beneficial. See you in our next article!