The Foundation of Data Organization: Exploring Key-Value Pairs
Related Articles: The Foundation of Data Organization: Exploring Key-Value Pairs
Introduction
With great pleasure, we will explore the intriguing topic related to The Foundation of Data Organization: Exploring Key-Value Pairs. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
The Foundation of Data Organization: Exploring Key-Value Pairs
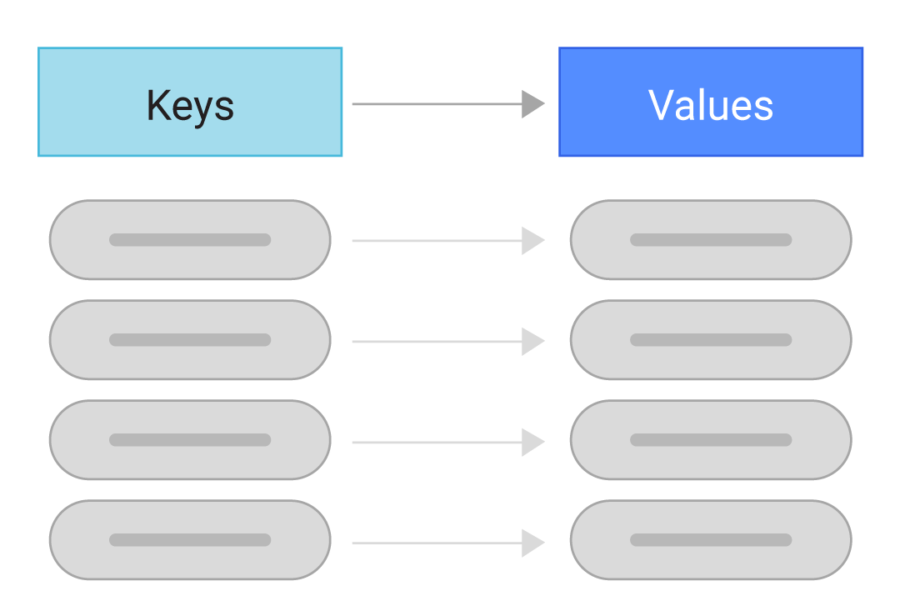
The concept of key-value pairs, often referred to as maps or dictionaries, is a fundamental building block in computer science and software development. This simple yet powerful data structure provides a highly efficient way to store and retrieve information, forming the basis for numerous applications across diverse domains.
Understanding the Essence: Key-Value Pairs
Imagine a real-world scenario where you need to store information about different cities. You might use a simple table with columns for "City Name" and "Population." Each row in this table represents a key-value pair:
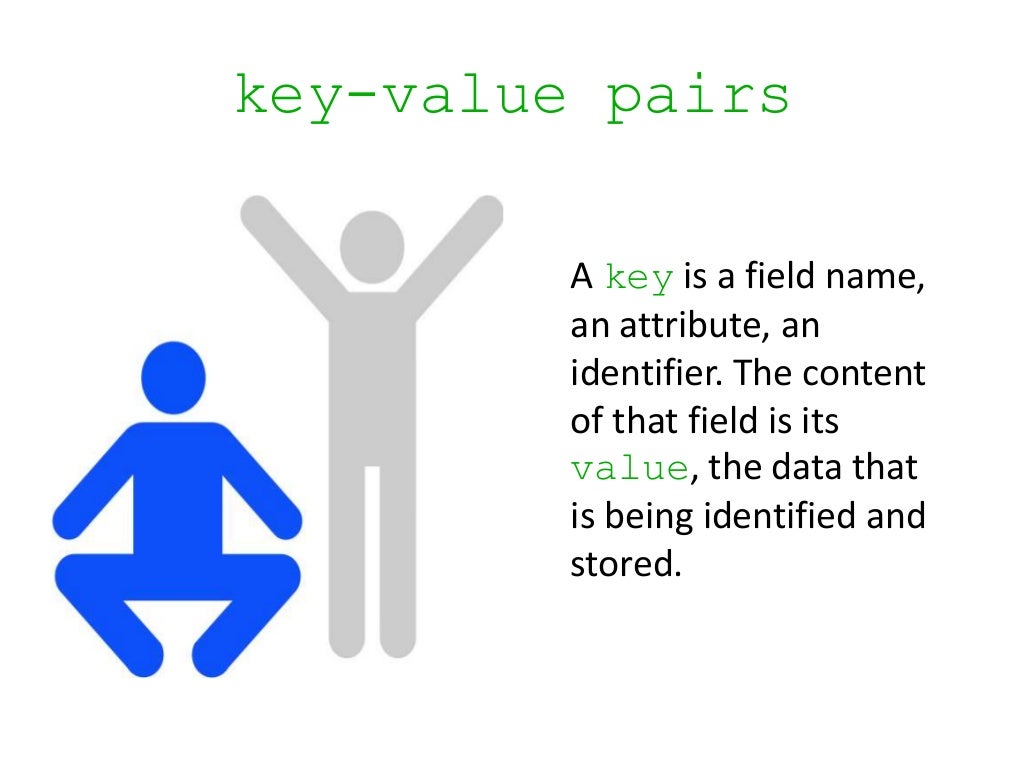
- Key: The city name (e.g., "New York City")
- Value: The corresponding population (e.g., "8,398,748")
This concept translates seamlessly into the digital world. Key-value pairs allow us to associate a unique identifier (the key) with a specific piece of data (the value).
Key Properties of Key-Value Pairs:
- Uniqueness: Keys within a map must be distinct. This ensures efficient retrieval, as each key points to a single, unambiguous value.
- Flexibility: Keys and values can be of various data types, allowing for versatile data representation. This enables storing diverse information, from simple integers to complex objects.
- Efficiency: Key-value pairs offer rapid access to data. Operations like searching, insertion, and deletion are highly optimized, making them ideal for applications demanding quick data retrieval.
Applications of Key-Value Pairs:
The versatility of key-value pairs makes them indispensable across a wide range of applications:
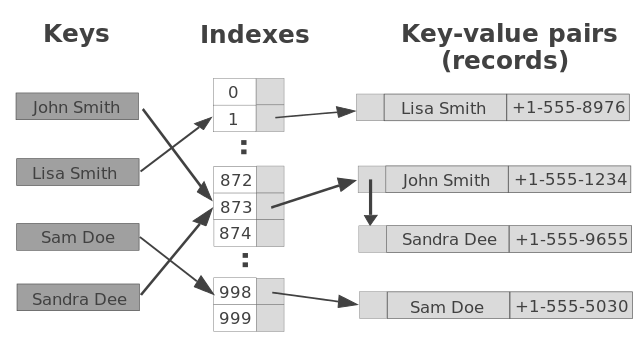
- Databases: Key-value stores are a popular choice for storing and retrieving data efficiently. Examples include Redis, MongoDB, and Amazon DynamoDB.
- Configuration Files: Key-value pairs are commonly used to store application settings, making configurations easy to read, modify, and manage.
- Caching: Key-value pairs excel in caching frequently accessed data, minimizing database queries and improving performance.
- Web Development: Key-value pairs are heavily utilized in web frameworks for storing session data, user preferences, and other dynamic information.
- Artificial Intelligence (AI): Key-value pairs are fundamental in AI algorithms for representing relationships between features and their associated values.
Benefits of Using Key-Value Pairs:
- Enhanced Organization: Key-value pairs provide a structured approach to data storage, making it easy to locate and manipulate specific pieces of information.
- Improved Efficiency: The inherent efficiency of key-value pairs leads to faster data access, resulting in better application performance.
- Simplified Development: Key-value pairs simplify data management, reducing the complexity of code and making development more efficient.
- Scalability: Key-value stores are designed to handle large datasets, making them suitable for applications with growing data needs.
Exploring Key-Value Pair Implementations:
Different programming languages offer various implementations of key-value pairs, each with its own strengths and characteristics:
- Python Dictionaries: Python’s built-in dictionaries provide a robust and versatile implementation of key-value pairs.
- Java HashMaps: Java’s HashMaps offer high performance and are widely used for storing and retrieving data efficiently.
- JavaScript Objects: JavaScript objects are essentially key-value pairs, making them central to JavaScript programming.
FAQs: Delving Deeper into Key-Value Pairs
1. What are the differences between a key-value pair and a tuple?
While both key-value pairs and tuples represent data in pairs, they differ in key aspects:
- Order: Tuples maintain order, while key-value pairs are unordered. This means the order of elements in a tuple is significant, whereas the order of key-value pairs is not.
- Mutability: Tuples are immutable, meaning their contents cannot be changed after creation. Key-value pairs are mutable, allowing for modification of values associated with keys.
- Uniqueness: Keys in key-value pairs must be unique, ensuring efficient retrieval. Tuples do not enforce uniqueness, allowing for duplicate elements.
2. How are key-value pairs used in machine learning?
Key-value pairs are fundamental in machine learning algorithms, particularly in feature engineering and model representation:
- Feature Engineering: Key-value pairs are used to represent features and their corresponding values, allowing for efficient feature extraction and transformation.
- Model Representation: Key-value pairs can store model parameters and hyperparameters, making it easier to manage and update machine learning models.
3. Can key-value pairs be used for storing large amounts of data?
Yes, key-value pairs are well-suited for storing large amounts of data. Key-value stores are designed for scalability and can handle massive datasets efficiently.
4. Are key-value pairs always the best choice for data storage?
While key-value pairs offer significant advantages, they may not be the optimal choice for all scenarios. For structured data requiring complex relationships, relational databases might be more appropriate.
Tips for Effective Use of Key-Value Pairs:
- Choose Appropriate Keys: Select keys that accurately represent the data being stored and are easily searchable.
- Use Consistent Data Types: Maintain consistent data types for keys and values within a single map to ensure predictable behavior.
- Optimize for Performance: Consider factors like data size and access patterns to choose the most efficient implementation for your needs.
- Handle Collisions: Be aware of potential hash collisions, especially when using hash-based implementations, and implement appropriate collision resolution strategies.
Conclusion: The Power of Simplicity
Key-value pairs, though seemingly simple, are a cornerstone of data organization and management. Their versatility, efficiency, and scalability make them invaluable across diverse applications, from web development and databases to machine learning and artificial intelligence. Understanding the fundamentals of key-value pairs empowers developers to build robust, efficient, and scalable systems, contributing to the advancement of technology in the digital age.




Closure
Thus, we hope this article has provided valuable insights into The Foundation of Data Organization: Exploring Key-Value Pairs. We hope you find this article informative and beneficial. See you in our next article!